


The Kubernetes Labs catalog just grew to 217 hands-on labs — the most complete path from your first Pod to operating production-grade clusters, all inside LearnXops.
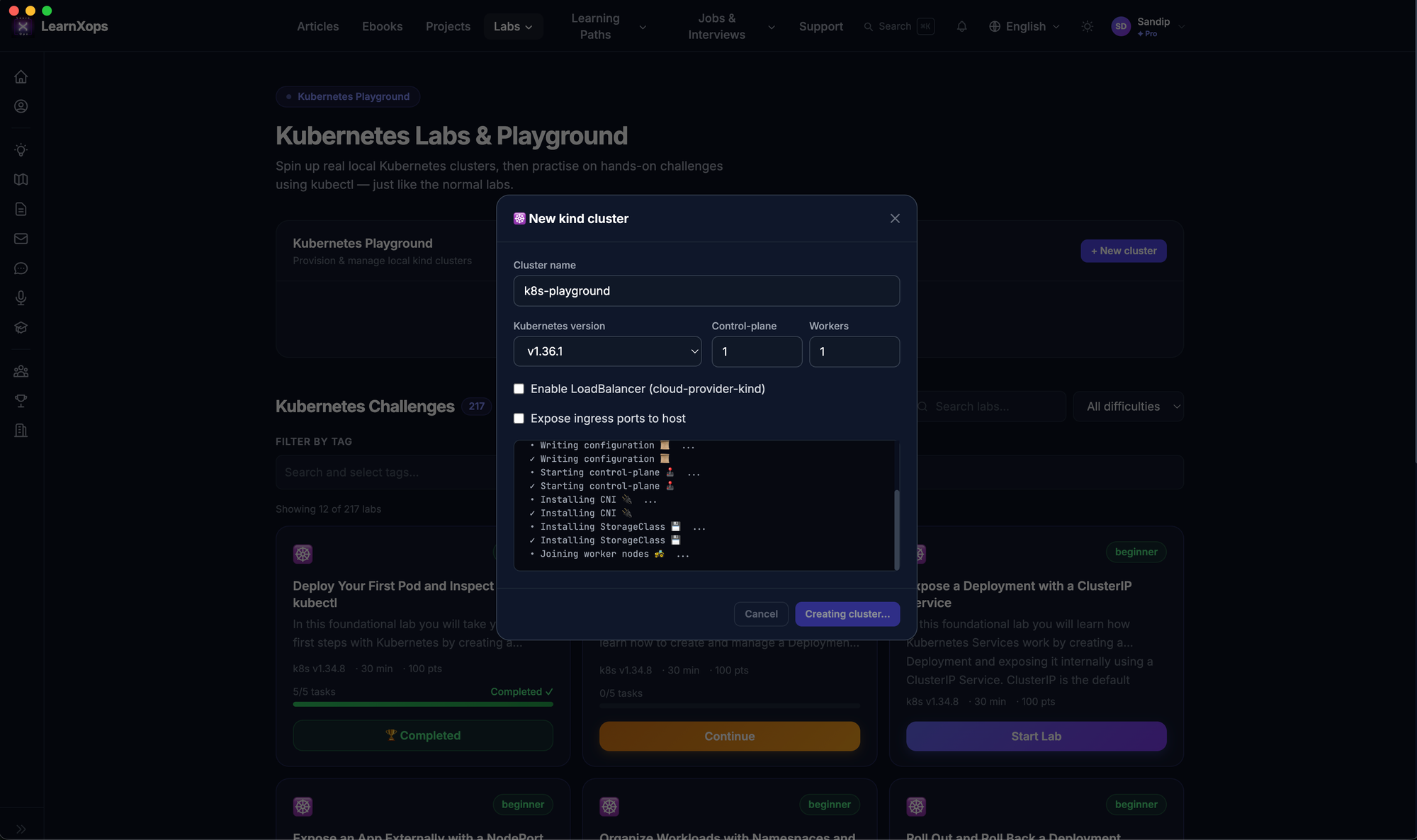
Most learning platforms give you very limited videos and quizzes and very few labs with a terminal which disconnects most of the time. We give you a terminal and a problem to solve using your local system.
Every lab on LearnXops:
- Runs inside your system's Docker environment
- Has step-by-step tasks with hints, verification and solutions
- Covers beginner to expert difficulty
🧩 Core Kubernetes (39 labs)
Workloads, objects, scheduling and the kubectl skills everything else builds on.
- Deploy Your First Pod and Inspect It with kubectl — Beginner · 100 pts
- Create a Deployment and Scale It Up and Down — Beginner · 100 pts
- Expose a Deployment with a ClusterIP Service — Beginner · 100 pts
- Expose an App Externally with a NodePort Service — Beginner · 100 pts
- Organize Workloads with Namespaces and Contexts — Beginner · 100 pts
- Roll Out and Roll Back a Deployment Update — Beginner · 100 pts
- Inject Configuration with ConfigMaps — Beginner · 100 pts
- Manage Sensitive Data with Kubernetes Secrets — Beginner · 100 pts
- Label, Select, and Annotate Kubernetes Objects — Beginner · 100 pts
- Run a One-Off Job and a Scheduled CronJob — Beginner · 100 pts
- Share Data Between Containers with emptyDir Volumes — Beginner · 100 pts
- Field Selectors and Advanced kubectl Output (jsonpath, custom-columns) — Beginner · 100 pts
- Run Workloads with ReplicaSets (and Why Deployments Win) — Beginner · 100 pts
- Init Containers: Order Pod Startup with Dependency Checks — Beginner · 100 pts
- Multi-Container Pods with the Sidecar Pattern — Beginner · 100 pts
- Self-Healing Pods with Liveness and Readiness Probes — Intermediate · 100 pts
- Set Resource Requests and Limits (and Trigger an OOMKill) — Intermediate · 100 pts
- Persist Data with PersistentVolumeClaims and StorageClasses — Intermediate · 100 pts
- Run a Stateful Database with a StatefulSet and Headless Service — Intermediate · 100 pts
- Schedule Pods with NodeSelectors, Affinity, and Taints/Tolerations — Intermediate · 100 pts
- Lock Down a Pod with RBAC (ServiceAccount, Role, RoleBinding) — Intermediate · 100 pts
- Restrict Pod-to-Pod Traffic with NetworkPolicies — Intermediate · 100 pts
- Pod Lifecycle Hooks: postStart and preStop — Intermediate · 100 pts
- Native Sidecar Containers with restartPolicy: Always — Intermediate · 100 pts
- Graceful Shutdown with terminationGracePeriodSeconds — Intermediate · 100 pts
- Downward API: Expose Pod Metadata to Containers — Intermediate · 100 pts
- Ephemeral Debug Containers with kubectl debug — Intermediate · 100 pts
- Manage Resources Declaratively with kubectl apply and Kustomize — Intermediate · 100 pts
- Patch Resources with Strategic Merge and JSON Patch — Intermediate · 100 pts
- TTL Controller: Auto-Clean Finished Jobs — Intermediate · 100 pts
- Run a DaemonSet Across All Nodes — Advanced · 100 pts
- Zero-Downtime Rolling Updates with maxSurge / maxUnavailable — Advanced · 100 pts
- Static Pods Managed Directly by the Kubelet — Advanced · 100 pts
- IndexedJob and Parallel Job Completions in Kubernetes — Advanced · 100 pts
- Pod Priority and Preemption with PriorityClasses — Advanced · 100 pts
- Server-Side Apply and Field Management in Kubernetes — Advanced · 100 pts
- Mutate, Validate, and Generate Resources with Kyverno — Advanced · 100 pts
- Spread Workloads with Pod Topology Spread Constraints — Advanced · 100 pts
- Multi-Node Scheduling, Cordon, Drain, and Node Maintenance — Expert · 100 pts
⎈ Helm — Packaging & Releases (10 labs)
Charts, dependencies, hooks, and multi-environment release management.
- Install and Manage an App with Helm Charts — Intermediate · 100 pts
- Helm Chart Dependencies and Subcharts — Intermediate · 100 pts
- Helm Release Lifecycle: Upgrade, Rollback, and History — Intermediate · 100 pts
- Manage Multi-Environment Releases with Helm Values Files — Intermediate · 100 pts
- Test Your Helm Chart with helm test Hooks — Intermediate · 100 pts
- Author Your Own Helm Chart with Values and Templates — Advanced · 100 pts
- Helm Hooks for Pre/Post Install Jobs — Advanced · 100 pts
- Template Logic with Named Templates and _helpers.tpl — Advanced · 100 pts
- Validate Chart Inputs with values.schema.json — Advanced · 100 pts
- Package and Host a Helm Chart Repository — Advanced · 100 pts
🌐 Networking (17 labs)
Services, DNS, Ingress, the Gateway API, NetworkPolicies and service mesh.
- Route HTTP Traffic with an Ingress Controller — Intermediate · 100 pts
- Expose a Service of type LoadBalancer (cloud-provider-kind) — Intermediate · 100 pts
- Headless Services and DNS-Based Service Discovery — Intermediate · 100 pts
- Cluster DNS Deep Dive: CoreDNS, FQDN Resolution, and DNS Debugging — Intermediate · 100 pts
- ExternalName Services: Map In-Cluster Names to External Endpoints — Intermediate · 100 pts
- Path- and Host-Based Routing with a Single Ingress — Intermediate · 100 pts
- Expose Multiple Ingress Hosts with the NGINX Ingress Controller — Intermediate · 100 pts
- Bare-Metal LoadBalancer with MetalLB (L2 Mode) — Intermediate · 100 pts
- TLS Termination at the Ingress with Kubernetes Secrets — Advanced · 100 pts
- EndpointSlices: How Services Track Pod Endpoints — Advanced · 100 pts
- The Gateway API: Routes, Gateways, and GatewayClasses — Advanced · 100 pts
- Default-Deny NetworkPolicies and Egress Control — Advanced · 100 pts
- Zero-Trust mTLS Between Services with Linkerd — Advanced · 100 pts
- Dual-Stack Networking (IPv4/IPv6) on kind — Expert · 100 pts
- Traffic Management with Istio (Sidecar, VirtualService, DestinationRule) — Expert · 100 pts
- Progressive Traffic Shifting and Mirroring with Istio — Expert · 100 pts
- eBPF Networking and Flow Observability with Cilium + Hubble — Expert · 100 pts
💾 Storage & Data (11 labs)
Volumes, PVCs, StatefulSet storage, snapshots, and backup/restore.
- Mount ConfigMaps and Secrets as Volumes (with subPath) — Beginner · 100 pts
- Dynamic Provisioning vs Static PersistentVolumes — Intermediate · 100 pts
- Reclaim Policies: Retain, Delete, and Their Trade-offs — Intermediate · 100 pts
- Projected Volumes: Combine Secrets, ConfigMaps, and Tokens — Intermediate · 100 pts
- Resize a PersistentVolumeClaim Online — Intermediate · 100 pts
- VolumeSnapshots: Back Up and Restore Stateful Data — Advanced · 100 pts
- StatefulSet volumeClaimTemplates and Per-Pod Storage — Advanced · 100 pts
- Local PersistentVolumes and Node-Bound Storage — Advanced · 100 pts
- Back Up and Restore Cluster State with Velero and MinIO — Advanced · 100 pts
- Scheduled Backups and a Disaster-Recovery Drill with Velero — Advanced · 100 pts
- Back Up and Restore etcd with etcdctl Snapshots — Advanced · 100 pts
🔐 Security (24 labs)
RBAC, admission control, Pod Security, secrets, supply-chain and runtime defense.
- ServiceAccount Tokens and Projected Token Volumes — Intermediate · 100 pts
- RBAC ClusterRoles and ClusterRoleBindings Across Namespaces — Intermediate · 100 pts
- Audit Permissions with kubectl auth can-i and Impersonation — Intermediate · 100 pts
- Drop Linux Capabilities and Run as Non-Root — Intermediate · 100 pts
- Image Pull Secrets for Private Registries — Intermediate · 100 pts
- Benchmark Cluster Hardening with kube-bench (CIS) — Intermediate · 100 pts
- Scan Images and Live Workloads for CVEs with Trivy — Intermediate · 100 pts
- Harden Workloads with Pod Security Standards and SecurityContext — Advanced · 100 pts
- Enforce Pod Security Admission at the Namespace Level — Advanced · 100 pts
- Read-Only Root Filesystems and seccomp Profiles — Advanced · 100 pts
- Aggregated ClusterRoles for Extensible Permissions — Advanced · 100 pts
- Bound ServiceAccount Tokens for Workload Identity — Advanced · 100 pts
- Issue and Auto-Renew TLS Certificates with cert-manager — Advanced · 100 pts
- Sync External Secrets with the External Secrets Operator — Advanced · 100 pts
- Inject Secrets at Runtime with HashiCorp Vault Agent — Advanced · 100 pts
- Enforce Policy with OPA Gatekeeper Constraints — Advanced · 100 pts
- Issue a Client Certificate and Build a kubeconfig for a New User — Advanced · 100 pts
- Enable API Server Audit Logging and Trace an Action — Advanced · 100 pts
- Sign Images with cosign and Enforce Signatures at Admission — Advanced · 100 pts
- Detect Runtime Threats with Falco — Advanced · 100 pts
- ValidatingAdmissionPolicy with CEL Expressions — Expert · 100 pts
- Block Workloads with a Validating Admission Webhook — Expert · 100 pts
- Encrypt Secrets at Rest with an EncryptionConfiguration — Expert · 100 pts
- Sandbox Untrusted Workloads with RuntimeClass (gVisor) — Expert · 100 pts
📊 Observability (13 labs)
Logs, metrics, tracing, dashboards, alerting and SLOs.
- Stream and Aggregate Pod Logs with kubectl — Beginner · 100 pts
- Inspect Cluster State with Events and kubectl describe — Beginner · 100 pts
- Install metrics-server and Read Pod/Node Metrics — Intermediate · 100 pts
- Profile Resource Usage with the Metrics API — Intermediate · 100 pts
- Startup Probes for Slow-Starting Applications — Intermediate · 100 pts
- Deploy Prometheus and Scrape Application Metrics — Advanced · 100 pts
- Visualize Metrics with Grafana Dashboards — Advanced · 100 pts
- Instrument an App with Custom Prometheus Metrics — Advanced · 100 pts
- Alerting Rules with Prometheus Alertmanager — Advanced · 100 pts
- Structured Logging with Fluent Bit to a Sink — Advanced · 100 pts
- Aggregate Logs with Loki and Grafana — Advanced · 100 pts
- Define SLOs with Prometheus and Multi-Window Burn-Rate Alerts — Advanced · 100 pts
- Distributed Tracing with OpenTelemetry and Jaeger — Expert · 100 pts
🤖 Operators & CRDs (15 labs)
Custom resources, controllers, the Operator SDK and real-world operators.
- Build a Custom Resource and Reconcile It with an Operator (kubebuilder/CRD basics) — Advanced · 100 pts
- Define a CustomResourceDefinition with Validation Schemas — Advanced · 100 pts
- Add Printer Columns and Subresources to a CRD — Advanced · 100 pts
- Finalizers: Clean Up External Resources on Delete — Advanced · 100 pts
- Install an Operator from OperatorHub with OLM — Advanced · 100 pts
- Run a Private Image Registry with Harbor — Advanced · 100 pts
- Isolate Tenants with Virtual Clusters (vcluster) — Advanced · 100 pts
- Attribute Kubernetes Spend with OpenCost — Advanced · 100 pts
- Run Production PostgreSQL with the CloudNativePG Operator — Advanced · 100 pts
- Scaffold an Operator with the Operator SDK — Expert · 100 pts
- Build a Controller with the client-go Informer Pattern — Expert · 100 pts
- CRD Versioning and Conversion Webhooks — Expert · 100 pts
- Implement a Reconcile Loop with Owner References — Expert · 100 pts
- Run Virtual Machines on Kubernetes with KubeVirt — Expert · 100 pts
- Platform Engineering with Crossplane — Expert · 100 pts
🔄 GitOps & Delivery (12 labs)
Argo CD, Flux, progressive delivery, in-cluster CI and developer inner-loop.
- Drift Detection and Reconciliation Fundamentals — Intermediate · 100 pts
- Fast Inner-Loop Development with Skaffold — Intermediate · 100 pts
- Catch Deprecated and Invalid Manifests Before Apply (kubeconform + Pluto) — Intermediate · 100 pts
- GitOps Deploy with Argo CD on kind — Advanced · 100 pts
- Argo CD Auto-Sync and Self-Heal — Advanced · 100 pts
- Argo CD App-of-Apps Pattern — Advanced · 100 pts
- Manage Clusters Declaratively with Flux CD — Advanced · 100 pts
- Flux Helm Releases from Git — Advanced · 100 pts
- Multi-Environment Promotion with Kustomize Overlays in GitOps — Advanced · 100 pts
- Build Container Images In-Cluster with Kaniko — Advanced · 100 pts
- Run a CI Pipeline on Kubernetes with Tekton — Advanced · 100 pts
- Progressive Delivery with Argo Rollouts (Canary) — Expert · 100 pts
📈 Scaling & Capacity (13 labs)
HPA, VPA, KEDA, quotas, autoscaling and right-sizing.
- Resource Quotas and LimitRanges per Namespace — Intermediate · 100 pts
- Protect Availability with PodDisruptionBudgets during a Drain — Intermediate · 100 pts
- Autoscale Workloads with the Horizontal Pod Autoscaler — Advanced · 100 pts
- Blue-Green and Canary Deployments by Hand — Advanced · 100 pts
- HPA with Memory and Multiple Metrics — Advanced · 100 pts
- Tune HPA Behavior with scaleUp/scaleDown Policies — Advanced · 100 pts
- Vertical Pod Autoscaler: Right-Size Your Workloads — Advanced · 100 pts
- Cluster Autoscaling Concepts on kind — Advanced · 100 pts
- Custom Metrics Autoscaling with the Prometheus Adapter — Advanced · 100 pts
- Resize Pod CPU/Memory In-Place Without a Restart — Advanced · 100 pts
- KEDA: Event-Driven Autoscaling from a Queue — Expert · 100 pts
- Rebalance Workloads with the Descheduler — Expert · 100 pts
- Dynamic Resource Allocation (DRA): Claim Devices with ResourceClaims — Expert · 100 pts
🔧 Troubleshooting & SRE (15 labs)
Diagnose and recover real failures — crashes, scheduling, DNS, nodes, chaos.
- Resolve ImagePullBackOff and ErrImagePull — Beginner · 100 pts
- Diagnose Pending Pods: Scheduling and Insufficient Resources — Intermediate · 100 pts
- Fix CrashLoopBackOff: Logs, Exit Codes, and Probes — Intermediate · 100 pts
- Debug Service Connectivity: Endpoints, Selectors, and DNS — Intermediate · 100 pts
- Debug RBAC Forbidden Errors — Intermediate · 100 pts
- Investigate OOMKilled and Evicted Pods — Intermediate · 100 pts
- Network Debugging with a netshoot Toolbox Pod — Intermediate · 100 pts
- QoS Classes and the Eviction Order Under Node Pressure — Intermediate · 100 pts
- Debug a Broken Cluster: CrashLoopBackOff, ImagePullBackOff, and Pending Pods — Advanced · 100 pts
- Troubleshoot Failed PVC Binding and Volume Mounts — Advanced · 100 pts
- Recover a Stuck Namespace Termination (Finalizers) — Advanced · 100 pts
- Inject Faults and Test Resilience with Chaos Mesh — Advanced · 100 pts
- Debug a Failing Admission Webhook Blocking All Deployments — Advanced · 100 pts
- Trace Node NotReady and Kubelet Issues — Expert · 100 pts
- Game Day: Diagnose a Multi-Failure Cluster — Expert · 100 pts
🧠 AI / ML / MLOps on Kubernetes (48 labs)
Serving, training, GPUs, pipelines, feature stores, drift, notebooks and cost.
- Serve a scikit-learn Model as a REST API on Kubernetes — Beginner · 100 pts
- Run a Training Job to Completion and Persist the Model — Beginner · 100 pts
- Deploy a FastAPI ML Inference Service and Load-Test It — Intermediate · 100 pts
- Install KServe and Serve a Model with an InferenceService — Intermediate · 100 pts
- Batch (Offline) Inference as a Parallel Kubernetes Job — Intermediate · 100 pts
- Simulate GPU Scheduling on kind with a Fake GPU Device Plugin — Intermediate · 100 pts
- Schedule Periodic Retraining with an Argo CronWorkflow — Intermediate · 100 pts
- Use MinIO as S3-Compatible Storage for Datasets and Models — Intermediate · 100 pts
- Run a Vector Database (Qdrant) on Kubernetes — Intermediate · 100 pts
- Log and Audit Model Predictions in Kubernetes — Intermediate · 100 pts
- Load-Test and Benchmark an Inference Service — Intermediate · 100 pts
- Version Datasets for Reproducible Training — Intermediate · 100 pts
- Provision Per-User Notebook Servers with Resource Limits — Intermediate · 100 pts
- Cache LLM/Embedding Responses to Cut Inference Cost — Intermediate · 100 pts
- KServe Canary Rollout Between Two Model Versions — Advanced · 100 pts
- Serve Multiple Models with Seldon Core — Advanced · 100 pts
- Scale Inference to Zero with KServe + Knative — Advanced · 100 pts
- Triton Inference Server: Multi-Framework Model Serving on Kubernetes — Advanced · 100 pts
- Serve a Small LLM on CPU with llama.cpp (GGUF) — Advanced · 100 pts
- Ray Serve for Online Model Inference on Kubernetes — Advanced · 100 pts
- Model Inference Gateway and Request Routing — Advanced · 100 pts
- Gang-Schedule ML Jobs with the Volcano Scheduler — Advanced · 100 pts
- Checkpoint and Resume Training Across Pod Restarts — Advanced · 100 pts
- Queue and Fair-Share ML Batch Jobs with Kueue — Advanced · 100 pts
- Distributed Data Processing with a Ray Cluster (KubeRay) — Advanced · 100 pts
- Schedule GPU Workloads with the NVIDIA Device Plugin — Advanced · 100 pts
- Monitor GPU Utilization with DCGM Exporter and Grafana — Advanced · 100 pts
- Enforce GPU Quotas and Fair Use per Namespace — Advanced · 100 pts
- Build and Run an ML Pipeline with Argo Workflows — Advanced · 100 pts
- Event-Driven ML Workflows with Argo Events — Advanced · 100 pts
- Serve Online Features with a Feature Store (Feast) on Kubernetes — Advanced · 100 pts
- Track Experiments and Models with MLflow on Kubernetes — Advanced · 100 pts
- Expose Inference Metrics (Latency, Throughput, Tokens) to Prometheus — Advanced · 100 pts
- Run JupyterHub on Kubernetes for Team Notebooks — Advanced · 100 pts
- Multi-Tenant Model Serving with Namespaces and Quotas — Advanced · 100 pts
- Blue-Green Model Deployment with Zero-Downtime Cutover — Advanced · 100 pts
- Rate-Limit and Add Guardrails to an LLM Endpoint — Advanced · 100 pts
- Warm-Pool Inference Pods to Reduce Cold Starts — Advanced · 100 pts
- Autoscale LLM Inference from a Queue with KEDA — Expert · 100 pts
- Distributed PyTorch Training with the Training Operator (PyTorchJob) — Expert · 100 pts
- Distributed TensorFlow with TFJob on Kubernetes — Expert · 100 pts
- Hyperparameter Tuning with Katib on Kubernetes — Expert · 100 pts
- All-Reduce Training with MPIJob and Horovod — Expert · 100 pts
- Fine-Tune a Small Language Model as a Job (LoRA, CPU) — Expert · 100 pts
- Share GPUs with Time-Slicing via the NVIDIA GPU Operator — Expert · 100 pts
- Kubeflow Pipelines: Compile and Run a Pipeline — Expert · 100 pts
- Detect Data and Model Drift on Kubernetes — Expert · 100 pts
- Cost-Aware Bin-Packing for Inference Workloads — Expert · 100 pts
Get Started
Pick a category you're working on, start a lab, and complete it. It takes anywhere from 15 minutes to an hour depending on difficulty.
Member discussion